










Table of Contents
See how Kapture can work for you
Join the 1000+ Enterprises who transformed their CX while reducing support costs.
Request DemoAbstract
The rapid adoption of Large Language Models (LLMs) has redefined enterprise AI, particularly within customer experience (CX). However, organizations deploying standalone generative systems are encountering systemic limitations: inconsistent accuracy, lack of real-time awareness, and minimal alignment with proprietary enterprise data.
Retrieval-Augmented Generation (RAG) emerges as a foundational architecture to address these constraints. By combining retrieval systems with generative models, RAG enables AI systems to ground outputs in enterprise-specific, real-time data, significantly improving factual accuracy and operational reliability.
This paper examines the architectural principles, performance implications, and enterprise deployment considerations of RAG, with a focus on Kapture’s implementation for CX environments.
1. The Enterprise AI Gap
Despite advances in generative AI, enterprises face a structural disconnect between model intelligence and organizational knowledge. Most LLMs operate as probabilistic systems trained on static datasets, whereas enterprise environments are dynamic, fragmented, and deeply contextual.
This gap manifests in three critical ways. First, responses lack determinism when domain-specific knowledge is required. Second, models fail to incorporate recent or transactional data. Third, outputs are often non-actionable, limiting AI to advisory roles rather than execution.
RAG addresses this gap by introducing a retrieval layer that acts as a bridge between enterprise data systems and generative reasoning.
2. RAG as a System Architecture
At its core, RAG is not a feature but a distributed system design pattern. It redefines the AI pipeline into two tightly coupled stages: retrieval and generation.
2.1 High-Level Architecture
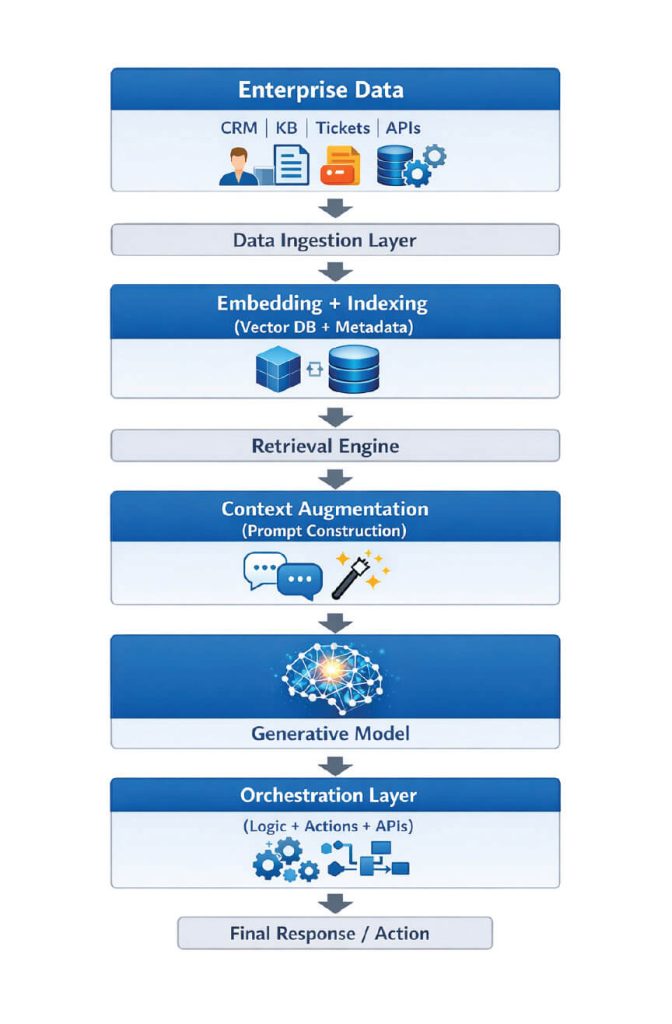
This architecture enables the system to dynamically retrieve relevant information, inject it into the model context, and generate outputs that are both linguistically coherent and factually grounded.
3. Kapture’s Enterprise RAG Stack
Kapture operationalizes RAG as a multi-layered system optimized for CX workflows, where latency, accuracy, and actionability are equally critical.
3.1 Knowledge Unification Layer
Rather than treating data sources independently, Kapture constructs a unified knowledge fabric. This layer normalizes structured and unstructured data into a consistent representation, enabling seamless retrieval across systems.
3.2 Hybrid Retrieval Architecture
Kapture employs a hybrid retrieval strategy combining semantic vector search with deterministic keyword filtering. This dual approach improves recall for ambiguous queries while maintaining precision for structured queries.
3.3 Context Engineering
A key differentiator lies in how context is constructed. Instead of naïvely appending retrieved documents, Kapture applies relevance scoring, redundancy elimination, and token optimization. This ensures that only high-signal data is passed to the model.
3.4 Action-Oriented Orchestration
Unlike traditional RAG pipelines, Kapture integrates an orchestration layer capable of executing workflows. This transforms the system from a passive responder into an active problem resolver.
4. Execution Flow in Kapture RAG
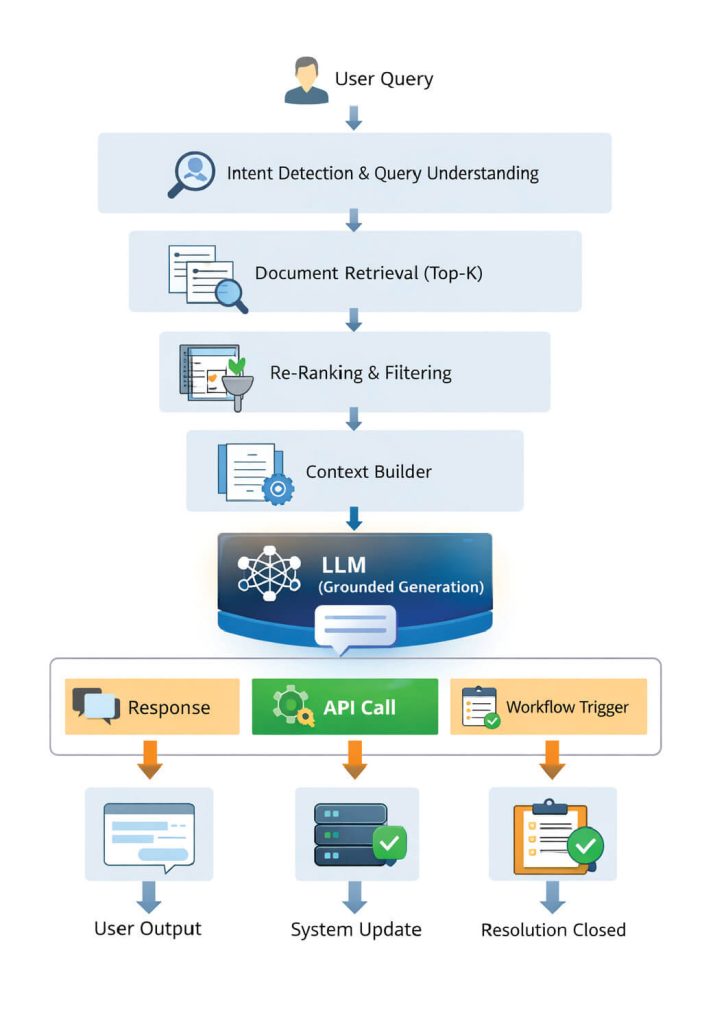
This flow illustrates how RAG transitions from information retrieval to full-cycle resolution.
5. Performance Metrics and Benchmarks
In enterprise deployments, the effectiveness of RAG systems is measured across multiple dimensions. Based on internal benchmarks and industry-aligned evaluations, the following improvements are typically observed when transitioning from standalone LLMs to RAG-based systems:
Accuracy (factual correctness) improves from approximately 70–75% to 90–95%, depending on data quality and retrieval precision.
Hallucination rates decrease significantly, often by 60–80%, as responses are grounded in verifiable sources.
First Response Time (FRT) in CX environments can be reduced by 30–50%, driven by instant retrieval and automated resolution.
Ticket deflection rates increase by 25–40%, as more queries are resolved without human intervention.
Operational cost reductions typically range between 20–35%, particularly in high-volume support environments.
Latency, often perceived as a trade-off, can be optimized to sub-second retrieval and 1–2 second end-to-end response times with efficient indexing and caching strategies.
6. Evaluation Framework
Evaluating RAG systems requires a shift from traditional NLP metrics to more holistic, system-level KPIs.
Retrieval quality is measured using metrics such as Recall@K and Mean Reciprocal Rank (MRR). Generation quality is evaluated through relevance, coherence, and groundedness. However, the most critical metric in CX environments is resolution success rate, which captures whether the AI system successfully completes the user’s intent.
A mature evaluation framework integrates offline benchmarking with real-time feedback loops, enabling continuous optimization.
7. Pseudo-Code: RAG Pipeline
Below is a simplified representation of a RAG pipeline as implemented in enterprise systems:
def rag_pipeline(user_query):
# Step 1: Understand query
intent = detect_intent(user_query)
# Step 2: Retrieve relevant documents
documents = retrieve_top_k(
query=user_query,
k=5,
method="hybrid_search"
)
# Step 3: Re-rank documents
ranked_docs = rerank(documents, user_query)
# Step 4: Build context
context = build_context(ranked_docs, token_limit=2000)
# Step 5: Generate response
response = llm.generate(
prompt=create_prompt(user_query, context)
)
# Step 6: Decide action
if requires_action(intent):
action_result = execute_workflow(intent, context)
return action_result
return response
This abstraction highlights the modular nature of RAG systems and their extensibility in enterprise environments.
8. Design Considerations
Implementing RAG at scale requires careful attention to system design. Data quality remains the most critical dependency; poor or outdated data will directly degrade system performance. Latency must be managed through efficient indexing, caching, and query optimization. Security considerations include role-based access control and data isolation, particularly when dealing with sensitive enterprise information.
Equally important is context management. Overloading the model with excessive or irrelevant context can reduce accuracy, making context engineering a key discipline within RAG implementations.
9. Strategic Implications for CX Leaders
RAG fundamentally shifts the role of AI in CX from automation to augmentation and ultimately to autonomy. Organizations adopting RAG are not merely improving response quality; they are redefining how knowledge is accessed and operationalized.
This has three strategic implications. First, knowledge management becomes a core AI competency rather than a support function. Second, AI systems evolve into execution engines capable of resolving customer issues end-to-end. Third, competitive differentiation increasingly depends on how effectively organizations leverage proprietary data within AI systems.
10. Conclusion
Retrieval-Augmented Generation represents a critical evolution in enterprise AI architecture. By grounding generative models in real-time, enterprise-specific data, RAG addresses the fundamental limitations of standalone LLMs.
Kapture extends this paradigm by integrating retrieval, reasoning, and execution into a unified system designed for CX. The result is not simply better responses, but measurable business outcomes: higher accuracy, faster resolution, and lower operational cost.
As enterprises move toward agentic AI systems, RAG will serve as the foundational layer enabling trust, scalability, and sustained competitive advantage.
Other blogs you’d love to read
Explore the advancements in CX and AI through Kapture.


Your Plan. Your Value. Your Growth.
Your business is different – and the pricing should reflect that.
Let’s build a plan that matches your goals, maximizes ROI, and scales with your success.









